
A group of Russian scientists have been working to create an artificial intelligence (AI) system that can process real time speech as a human does, such as in scenarios when two people are talking at once. These researchers are from Peter the Great St. Petersburg Polytechnic University (SPbPU) and have managed to simulate the process of coding sensory sounds by making a model of the mammalian auditory system. The results of their study can be found in the following article.
As per the SPbPU researchers, the human nervous system processes information as forms of neural responses. The peripheral nervous system is what provides physical perception of one’s external environment, using visual and auditory receptors. These receptors account for all of the transformation of external stimuli into higher level neural pathways, with peripheral nerves ensuring these signals then make it to the highest levels.
In essence, this allows a human to recognize one person’s specific voice in a noisy scenario, such as at a dinner party when many people are talking. Currently, there are no speech processing systems able to differentiate voice in this manner.
To tackle this challenge, the researchers of SPbPU’s ‘Measuring Information Technologies’ department developed methods for acoustic signal recognition based on peripheral coding. The researchers aimed to reproduce processes performed by the nervous system in processing auditory information, and to translate this process into a decision-making module that differentiates the type of incoming signal.
“The main goal is to give the machine human-like hearing, to achieve the corresponding level of machine perception of acoustic signals in the real-life environment,” said Anton Yakovenko, leading researcher. Yakovenko claims that examples of the responses to vowel phonemes produced by the auditory nerve model they created were represented in the dataset.
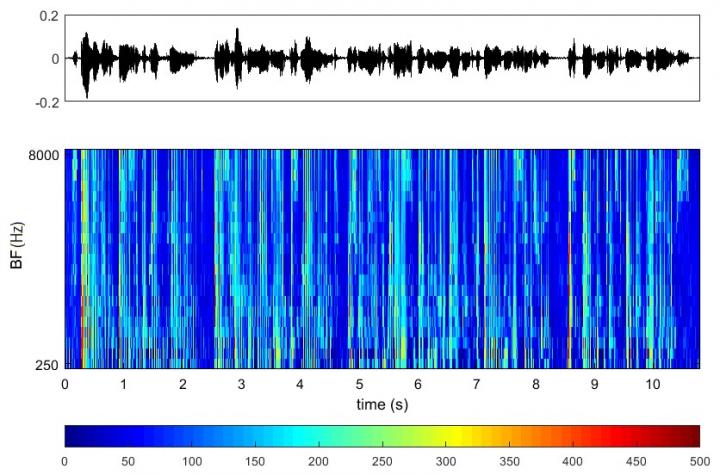
The data processing was conducted using a specific AI algorithm that conducted structural analysis to differentiate neural activity patterns used by the model to recognize each phoneme. The researchers’ proposed model includes use of self-organized neural networks and graph theory in concert. The scientists claim that the analysis of auditory nerve fibers allowed to correctly identify vowel phenomes in noisy environments surpassed common means of interpreting acoustic signals.
The research team believes that the methods used in this study will likely assist in creating a new generation of neurocomputer interfaces, bolstering interactions between human and machine. This study has great implication for practical uses, with surgical restoration of hearing, separation of auditory sources, and refined speech processing systems all being potential applications.
We can see you. We can feel you.
Now we can hear you. #WhatsInTheComputerLabhttps://t.co/QVVRQQomw8
— The Computer Lab: A Web Series (@ComputerLab) December 20, 2018
Source: RD Mag





 © 2025 Mashup Media, LLC, a Formedics Property. All Rights Reserved.
© 2025 Mashup Media, LLC, a Formedics Property. All Rights Reserved.